
L’image-to-text en intelligence artificielle générative transforme des images en descriptions textuelles - pas juste en lisant les mots dessus, mais en comprenant ce qu’elles représentent. C’est une avancée majeure pour l’accessibilité, surtout pour les personnes malvoyantes qui dépendent des lecteurs d’écran. Mais cette technologie n’est pas parfaite. Elle peut décrire un ramp d’accès comme « une structure en béton décorative » ou un panneau d’arrêt comme « un cercle rouge avec du texte blanc ». Ces erreurs ne sont pas anodines : elles peuvent être dangereuses.
Comment ça marche ?
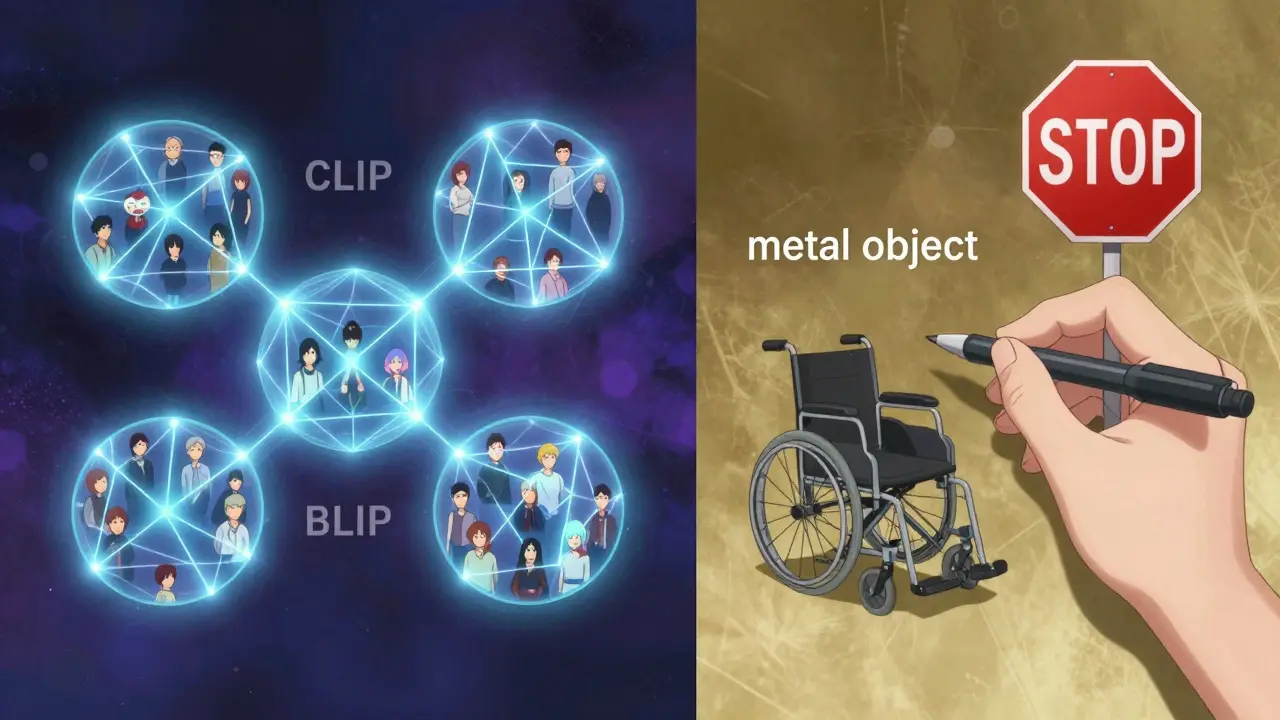
Les systèmes modernes comme CLIP (Contrastive Language-Image Pre-training) et BLIP (Bootstrapping Language-Image Pre-training) fonctionnent en apprenant à relier des images et des textes ensemble. Ils n’ont pas besoin d’être entraînés sur chaque type d’image. Ils apprennent sur des millions de paires image-texte provenant d’internet - des photos de chats, de rues, de personnes, de produits. Leur objectif : faire en sorte que la représentation numérique d’une image et celle d’une description qui la résume soient proches dans un espace mathématique commun.
CLIP, développé par OpenAI en 2021, utilise deux réseaux : un pour traiter l’image (un vision transformer), et un autre pour traiter le texte (un transformer classique). Quand vous donnez une image, le système la transforme en un vecteur numérique. Ensuite, il compare ce vecteur à des milliers de descriptions textuelles stockées, et choisit la plus proche. BLIP, sorti en 2022 par Salesforce, améliore ce processus en intégrant l’image directement dans la génération du texte, ce qui donne des descriptions plus naturelles et plus précises.
Des outils comme CLIP Interrogator, développé par Katherine Crowson, vont encore plus loin. Ils analysent une image et produisent une description complète : le sujet principal, le style artistique, l’ambiance, les éléments de composition. Tout ça en 2 à 3 secondes sur un GPU moderne. Mais ce n’est pas magique.
CLIP vs OCR : deux mondes différents
Beaucoup confondent l’image-to-text avec la reconnaissance optique de caractères (OCR). Ce n’est pas la même chose. L’OCR, comme Tesseract 5.0 de Google, lit les mots sur une image. Si vous avez un document scanné, il va extraire les lettres avec 98,5 % de précision. Mais il ne comprend pas ce que signifie l’image. Il ne peut pas dire « un enfant qui joue avec un chien » s’il n’y a pas de texte.
L’IA générative, elle, comprend le sens. Elle peut décrire une scène, une émotion, un contexte. Mais elle échoue sur les détails précis : compter 6 pommes dans un panier ? Elle en voit 3. Dire que le ciel est « bleu cobalt » ? Elle dit « bleu ». Reconnaître un fauteuil roulant ? Parfois, elle le voit comme un « objet métallique ».
Les chiffres parlent d’eux-mêmes. Sur le benchmark COCO (des milliers d’images annotées), CLIP atteint 65 à 75 % de précision. BLIP-2, sa version améliorée, monte à 89,2 %. Mais ces chiffres sont moyens. Ils cachent des échecs critiques. Par exemple, une étude de Salesforce montre que la précision chute à 45 % pour les images avec plus de 5 objets. Et si l’image contient une personne en fauteuil roulant ? La précision tombe à 68 %.
Les erreurs qui tuent l’accessibilité
Les utilisateurs en témoignent. Sur Reddit, un développeur a mis en place CLIP pour générer du texte alternatif sur un site d’association. Il a été enthousiaste au début : 80 % des images avaient une description correcte. Puis il a vu que « une rampe d’accès » était décrite comme « une structure en béton décorative ». Pour quelqu’un qui utilise un fauteuil roulant, cette erreur pourrait signifier qu’il ne saura pas où entrer.
Un autre utilisateur sur GitHub a écrit : « J’ai demandé à CLIP Interrogator de décrire un panneau d’arrêt. Il a dit : “cercle rouge avec du texte blanc”. Il n’a pas mentionné la forme de triangle, ni le mot “arrêt”. C’est un danger public. »
Une audit interne sur 2 500 images de produits a révélé que 37 % des descriptions pour les personnes de couleur étaient erronées ou biaisées. Les modèles ont été entraînés sur des images majoritairement occidentales. Les visages non caucasiens, les vêtements traditionnels, les environnements non urbains - ils sont mal compris. Selon une analyse de Timnit Gebru, CLIP a 28,7 % moins de précision sur les images issues de contextes non occidentaux.
Et ce n’est pas tout. Des chercheurs du MIT ont montré que des modifications invisibles à l’œil humain - un seul pixel changé - peuvent faire dire à l’IA que « une femme en robe noire » est « un homme en costume ». C’est une faille de sécurité majeure pour les systèmes qui doivent être fiables.
Qui utilise ça, et pourquoi ?
Pourtant, les entreprises l’adoptent. Zalando, la plateforme de mode européenne, a réduit ses coûts de taggage d’images de 60 % en utilisant CLIP. Shopify compte plus de 300 marchands qui génèrent automatiquement du texte alternatif pour leurs produits. Amazon et Google ont leurs propres versions : Titan Multimodal Embeddings et Imagen 2. Elles sont plus précises, mais réservées aux grandes entreprises.
Le marché de l’IA pour l’accessibilité vaut 1,3 milliard de dollars aujourd’hui, et devrait doubler d’ici 2028. Mais l’adoption est inégale. Les entreprises de e-commerce l’utilisent pour classer leurs produits. Les éditeurs numériques l’emploient pour automatiser les descriptions de photos. Mais pour l’accessibilité directe aux utilisateurs ? Très peu.
La raison ? La peur. L’Union européenne vient de passer l’AI Act. Il oblige les systèmes « à haut risque » - comme ceux utilisés pour l’accessibilité - à être certifiés. Si un système génère une description erronée qui empêche une personne de se déplacer en sécurité, l’entreprise peut être poursuivie. Donc, la plupart des entreprises utilisent l’IA pour l’interne, pas pour le public.
Les nouvelles versions, plus sûres ?
En janvier 2024, Salesforce a sorti BLIP-3. Ce modèle a été spécifiquement entraîné sur 50 000 images avec des descriptions conçues pour l’accessibilité. Il atteint 92,4 % de précision sur un nouveau benchmark appelé A11yCaption. Microsoft, de son côté, a intégré cette technologie dans Seeing AI, son application pour malvoyants. Selon leur équipe, les erreurs critiques ont baissé de 63 %.
Le W3C, l’organisme qui définit les normes du web, a publié en décembre 2023 une proposition : pour qu’un texte alternatif généré par l’IA soit considéré comme « sans supervision humaine », il doit atteindre 95 % de précision sur les éléments de sécurité - portes, rampes, panneaux, signaux. Aujourd’hui, aucun système ne le fait.
Les experts s’accordent : l’avenir n’est pas dans l’automatisation totale. C’est dans les workflows hybrides. L’IA génère une première description. Un humain la vérifie. Pour les images simples - un chat sur un canapé - l’IA suffit. Pour les images critiques - un panneau de signalisation, un ascenseur, un croisement - l’humain doit valider.

Comment l’implémenter ?
Si vous voulez essayer, voici ce dont vous avez besoin :
- Un serveur avec une GPU NVIDIA T4 ou mieux (minimum 16 Go de VRAM)
- Un environnement Python avec PyTorch ou TensorFlow
- Un modèle comme BLIP-2 ou CLIP Interrogator (disponibles sur Hugging Face)
- Un système de validation manuelle
Le coût ? Environ 3 $ l’heure pour faire tourner le modèle sur AWS. Le temps d’apprentissage ? 16 à 20 heures pour comprendre les bases de l’IA multimodale et les normes WCAG 2.1. Hugging Face propose des tutoriels clairs. OpenAI, moins.
Et n’oubliez pas : le texte alternatif n’est pas un décor. C’est une information essentielle. Une mauvaise description peut exclure, blesser, ou même mettre en danger.
Que faire maintenant ?
Ne supprimez pas l’IA. Mais ne la laissez pas seule. Utilisez-la comme un assistant, pas comme un juge. Testez sur vos propres images. Vérifiez les descriptions pour les personnes, les objets de sécurité, les contextes culturels. Documentez les erreurs. Partagez les données. Améliorez les modèles avec des jeux de données plus divers.
Les technologies de l’IA peuvent rendre le web plus accessible. Mais seulement si on les construit avec la communauté qu’elles veulent servir. Pas avec des données de 2021. Pas avec des modèles biaisés. Pas sans vérification humaine.
L’IA générative peut-elle remplacer le texte alternatif manuel ?
Non, pas encore. Les systèmes comme CLIP et BLIP génèrent des descriptions utiles pour les images simples, mais leur taux d’erreur sur les scènes complexes, les personnes ou les éléments de sécurité reste trop élevé. Pour l’accessibilité, le texte alternatif manuel reste la référence. L’IA peut aider à générer une première version, mais un humain doit toujours valider, surtout pour les contenus critiques.
Pourquoi les modèles d’IA font-ils des erreurs sur les personnes de couleur ?
Parce que les jeux de données d’entraînement sont biaisés. La majorité des images utilisées pour entraîner CLIP et BLIP viennent d’Internet et sont dominées par des scènes occidentales, avec des personnes blanches. Les visages, les vêtements, les expressions et les contextes culturels non occidentaux sont sous-représentés. Résultat : l’IA ne les reconnaît pas bien. Des études montrent jusqu’à 28,7 % de baisse de précision pour ces images. C’est un problème d’équité, pas seulement technique.
Quelle est la différence entre CLIP et BLIP ?
CLIP est un modèle de comparaison : il associe une image à un texte en mesurant leur similarité. BLIP, lui, est un modèle de génération : il crée du texte à partir de l’image en intégrant les informations visuelles directement dans sa structure. BLIP produit des descriptions plus longues, plus naturelles et plus précises. BLIP-2 et BLIP-3 ont amélioré la précision sur les benchmarks d’accessibilité, atteignant jusqu’à 92,4 %.
Est-ce que l’IA générative est légale pour le texte alternatif en Europe ?
Oui, mais avec des contraintes. L’AI Act européen classe les systèmes d’accessibilité comme « à haut risque ». Cela signifie qu’ils doivent être testés, documentés, et surveillés. Si un système génère un texte alternatif erronée qui cause un préjudice (par exemple, une personne se blesse en suivant une mauvaise description), l’entreprise peut être tenue responsable. Pour être légal, il faut une vérification humaine, une transparence sur les limites du modèle, et des tests sur des données diverses.
Quels sont les meilleurs outils gratuits pour essayer l’image-to-text ?
Pour les développeurs, les meilleurs outils gratuits sont : BLIP-2 (sur Hugging Face), CLIP Interrogator (sur GitHub), et l’API de Google Vision AI (avec un quota gratuit). Pour les utilisateurs non techniques, des extensions comme « Image Alt Text Generator » pour Chrome utilisent ces modèles en arrière-plan. Mais attention : même les meilleurs outils ont des erreurs. Ne les utilisez pas sans vérification.












