
Les grands modèles linguistiques (LLM) peuvent générer des réponses impressionnantes, mais ils ont un problème caché : ils ne se souviennent pas de tout. Même les modèles les plus récents, capables de traiter jusqu’à un million de tokens, échouent souvent avec des documents de plus de 100 pages. Pourquoi ? Parce que copier-coller tout un manuel juridique ou un rapport financier dans un prompt ne donne pas une réponse fiable - ça donne une hallucination. La solution ? Grounding. Pas juste un mot à la mode, mais une méthode concrète pour ancrer les réponses de l’IA dans des documents réels.
Le problème des longs documents
Imaginez que vous travaillez dans un cabinet d’avocats. Un client vous envoie un contrat de 150 pages. Vous demandez à votre LLM : « Quelles sont les clauses de résiliation ? » Le modèle répond avec une phrase qui semble juste. Mais en vérifiant, vous découvrez qu’il a mélangé deux sections différentes, inventé un délai de préavis qui n’existe pas, et ignoré une clause cruciale en annexe. C’est ce qu’on appelle une hallucination. Selon une étude de Stanford HAI en 2024, sans ancrage, les LLM commettent jusqu’à 27 % d’hallucinations dans les documents complexes. Les modèles ne peuvent pas lire 150 pages en une fois. Même avec des fenêtres de contexte de 32 000 tokens, le problème n’est pas la taille - c’est la cohérence. Quand vous coupez un document en morceaux, vous perdez les liens entre les paragraphes. Une clause mentionnée à la page 20 peut être cruciale pour comprendre une autre à la page 120. Sans structure, l’IA ne voit que des fragments. Et des fragments, ce n’est pas de la compréhension.Comment le RAG hiérarchique résout ce problème
Le RAG (Retrieval-Augmented Generation) classique récupère des morceaux de texte pertinents et les envoie à l’IA pour qu’elle réponde. Mais avec des documents longs, ça ne suffit pas. Le RAG hiérarchique ajoute une couche : il résume d’abord, puis il cherche. Voici comment ça marche en pratique :- Le document est divisé en blocs de 1 000 à 2 000 tokens (environ 750 à 1 500 mots), avec un chevauchement de 200 tokens pour ne pas couper des phrases importantes.
- Chaque bloc est résumé par un LLM. Ce n’est pas un résumé humain - c’est une version condensée, fidèle, qui garde les faits clés, les noms, les dates, les obligations.
- Les résumés sont stockés dans une base de données vectorielle, avec des métadonnées qui indiquent leur origine (ex : « section 4.2 du contrat X »).
- Quand une question est posée, le système cherche d’abord dans les résumés, pas dans les blocs bruts.
- Si la réponse nécessite plus de contexte, il récupère les blocs originaux correspondants.
- Enfin, le LLM génère la réponse en s’appuyant sur les résumés ET les extraits originaux.
La méthode Map/Reduce : la technique la plus efficace
La méthode la plus utilisée dans les entreprises est le Map/Reduce, inspirée des systèmes de traitement de données massives. Voici comment elle fonctionne :- Map : chaque bloc de document est traité en parallèle. Un LLM résume chaque bloc indépendamment. C’est la phase « map ». Google Cloud a montré que cette approche réduit le temps de traitement de 63 % par rapport à une méthode séquentielle.
- Reduce : les résumés des blocs sont ensuite regroupés en sections plus grandes (ex : chapitres), puis résumés à nouveau. Ce deuxième résumé capture les liens entre les parties du document.
- Final : un dernier résumé au niveau du document entier est créé, qui résume les résumés. C’est la couche la plus haute.
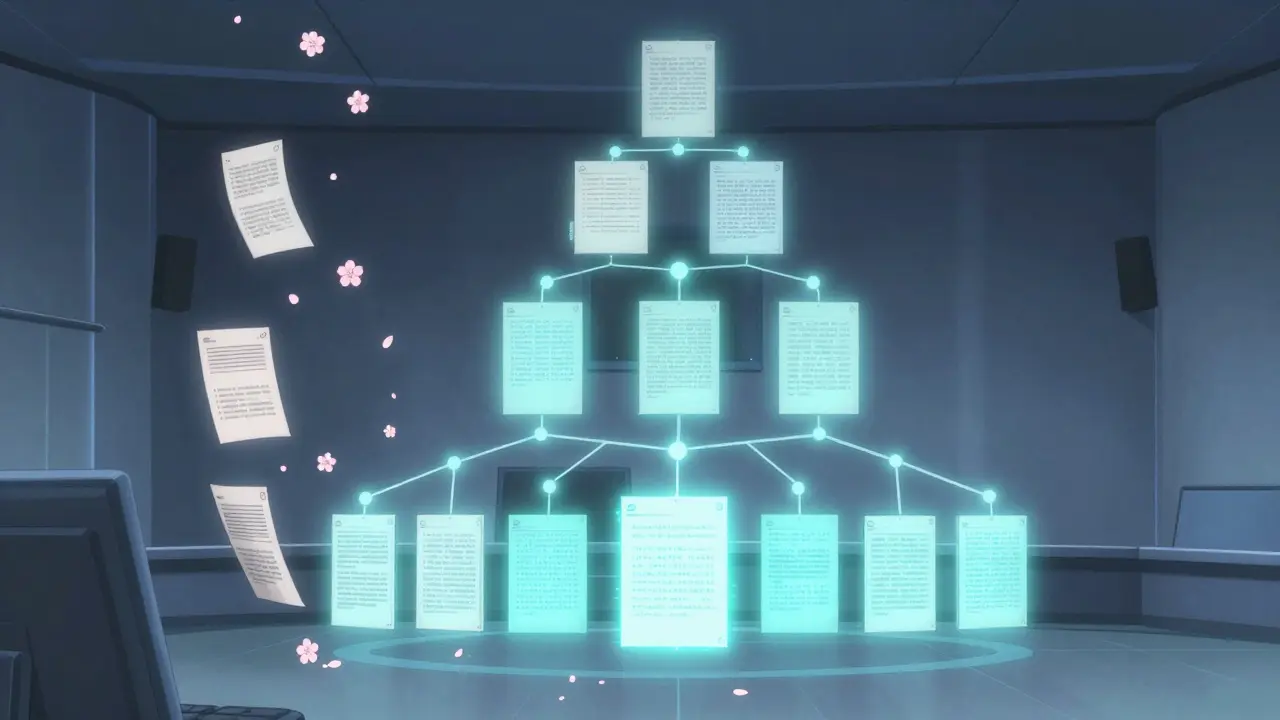
Les pièges courants et comment les éviter
Ce n’est pas magique. Beaucoup d’équipes échouent en implémentant ce système. Voici les erreurs les plus fréquentes :- Chaque bloc trop grand : si vous mettez 5 000 tokens par bloc, le résumé devient trop vague. L’IA perd les détails importants. Optez pour 1 000-2 000 tokens.
- Pas de chevauchement : couper une phrase entre deux blocs fait perdre du sens. Un chevauchement de 15-20 % est essentiel.
- Ignorer les entités : si vous ne gardez pas les noms, les dates, les chiffres dans les résumés, l’IA ne peut pas répondre avec précision. Des outils comme LlamaIndex permettent d’extraire automatiquement les entités (personnes, organisations, montants) pendant le résumé.
- Ne pas tester la cohérence : un résumé de section peut être correct, mais s’il contredit un autre résumé, c’est un désastre. Des équipes comme Microsoft utilisent des algorithmes de clustering sémantique pour regrouper les résumés similaires et détecter les contradictions.
Qui utilise ça ? Et pourquoi ça marche
Les entreprises qui ont adopté cette méthode ne la lâchent plus. Dans les services financiers, les résumés hiérarchiques permettent de vérifier automatiquement les conformités réglementaires. Aux États-Unis, la SEC exige depuis janvier 2025 que chaque réponse générée par l’IA soit tracée jusqu’à sa source. Le RAG hiérarchique est la seule méthode qui le permet. Un cas concret : une banque d’investissement traitait 800 contrats par mois. Chaque contrat prenait 45 minutes à analyser manuellement. Avec un pipeline RAG hiérarchique, le temps est tombé à 8 minutes. Le taux d’erreurs est passé de 18 % à 3 %. L’équipe a passé trois semaines à ajuster la taille des blocs et le chevauchement. Mais maintenant, le système tourne en production, 24/7. Les avocats utilisent la même méthode pour analyser les précédents juridiques. Les médecins, pour résumer des dossiers patients de plusieurs centaines de pages. Même les grandes entreprises de tech, comme Mozilla et Instagram, utilisent des variantes de cette approche pour gérer leurs milliers de documents internes.Les outils pour commencer
Vous n’avez pas besoin de tout construire depuis zéro. Trois outils dominent le marché :- LangChain : le plus populaire. Il a des templates prêts à l’emploi pour le Map/Reduce. La documentation est claire, mais il faut connaître Python.
- LlamaIndex : plus orienté performance. Il gère mieux l’extraction d’entités et le clustering sémantique. Idéal pour les documents techniques.
- Vespa : moins connu, mais très rapide pour les requêtes en temps réel. Utilisé par des entreprises comme Spotify pour des cas de recherche complexe.

Coût, compétences et retour sur investissement
Implémenter ça demande du temps. Une équipe expérimentée met 2 à 3 semaines pour un système de base. Ensuite, 1 à 2 semaines pour l’optimisation. Le coût ? Entre 35 et 50 heures de travail pour configurer les blocs, les résumés et la recherche. Mais le retour est clair. Selon Gartner, le marché du RAG a atteint 2,4 milliards de dollars en 2024, avec une croissance de 68 % par an. Les entreprises qui l’ont adopté voient une réduction de 40 % du temps de traitement des documents. Pour un cabinet juridique ou une banque, ça représente des millions d’euros par an. Les compétences requises ?- Connaissance intermédiaire du traitement du langage naturel (NLP)
- Expérience avec les bases de données vectorielles (Chroma, Pinecone, Weaviate)
- Compétence en prompt engineering pour les résumés
Qu’est-ce qui vient ensuite ?
Les prochaines évolutions vont encore améliorer ça. Google Cloud a lancé en novembre 2024 une fonctionnalité qui ajuste automatiquement la taille des blocs selon le type de document. Microsoft propose maintenant d’expander la requête de l’utilisateur en 3 variantes sémantiques pour trouver plus de bons résultats. D’ici 2026, selon Forrester, 95 % des implémentations RAG utiliseront un système à trois niveaux : résumé de bloc, résumé de section, résumé de document entier. Ce n’est plus une option - c’est la norme. Le vrai défi aujourd’hui ? Mesurer l’efficacité. Seulement 32 % des entreprises ont des métriques standardisées pour dire si leur RAG fonctionne bien. C’est pourquoi les outils de validation vont devenir un marché de 1,2 milliard de dollars d’ici 2026.Conclusion : ce n’est pas une option, c’est une nécessité
Les LLM sont puissants. Mais sans ancrage, ils sont dangereux. Dans un monde où les documents sont de plus en plus longs, où les enjeux sont plus élevés, et où les régulations exigent de la traçabilité, le RAG hiérarchique n’est pas une technique avancée - c’est le minimum. Vous ne pouvez plus vous permettre de laisser une IA répondre à une question sur un contrat sans savoir d’où elle tire sa réponse. Le résumé hiérarchique, c’est la clé pour transformer les LLM de générateurs d’hallucinations en assistants fiables. C’est l’avenir. Et il est déjà là.Quelle est la différence entre RAG classique et RAG hiérarchique ?
Le RAG classique cherche directement dans les morceaux du document brut. Le RAG hiérarchique résume d’abord les morceaux, puis les regroupe en résumés de sections et de documents entiers. Il cherche d’abord dans les résumés, puis descend vers les détails si nécessaire. Cela réduit les erreurs et accélère la recherche.
Pourquoi les résumés créent-ils moins d’hallucinations ?
Parce que les résumés sont conçus pour conserver les faits clés, les noms, les dates et les obligations, tout en supprimant le bruit. L’IA ne reçoit pas 10 000 mots flous - elle reçoit 300 mots précis. Moins de texte = moins d’ambiguïté = moins d’erreurs.
Quelle taille de bloc est optimale pour un document juridique ?
Entre 1 000 et 2 000 tokens, avec un chevauchement de 15 à 20 %. Les contrats ont des phrases complexes et des références croisées. Des blocs trop grands perdent la précision ; des blocs trop petits coupent les liens logiques. Cette plage a été validée par LangChain et par des équipes juridiques en production.
Est-ce que je dois tout réécrire avec LangChain ?
Non. LangChain et LlamaIndex proposent des modèles prêts à l’emploi pour le Map/Reduce. Vous n’avez qu’à remplacer les fichiers PDF par vos documents, configurer la base vectorielle, et lancer le pipeline. Le code est disponible sur GitHub. La difficulté, c’est l’ajustement, pas la construction.
Est-ce que ça marche avec des PDF ou des scans ?
Ça marche avec des PDF textuels, oui. Mais pas avec des scans ou des images. Vous devez d’abord extraire le texte avec un outil comme PDFMiner ou Tesseract. Si le texte est mal extrait (ex : des caractères bizarres, des mots coupés), le résumé sera erroné. La qualité de l’entrée détermine la qualité de la sortie.
Combien de temps faut-il pour voir des résultats concrets ?
Avec une équipe expérimentée, vous pouvez avoir un prototype opérationnel en 2 semaines. Mais pour que ça fonctionne bien - avec une précision supérieure à 85 % - il faut 3 à 4 semaines d’ajustements : taille des blocs, chevauchement, prompt de résumé, et tests sur vos documents réels. Les premiers gains viennent après 10 documents traités.
Est-ce que ça coûte cher en ressources ?
C’est plus coûteux qu’un RAG simple, car vous faites plusieurs appels à l’IA (résumé des blocs, résumé des résumés). Mais vous gagnez en vitesse globale : le traitement parallèle réduit le temps total de 63 %. Et vous réduisez les erreurs coûteuses. Pour les entreprises, le coût des hallucinations (litiges, erreurs financières) est bien plus élevé que le coût du traitement.
Quels sont les meilleurs cas d’usage pour cette méthode ?
Les documents longs, structurés, avec des enjeux élevés : contrats juridiques, rapports financiers, dossiers médicaux, documents réglementaires, brevets techniques. Ce n’est pas utile pour un article de blog de 500 mots. Mais pour un manuel de 200 pages ? C’est indispensable.










