Beaucoup d’équipes commencent leur projet d’intelligence artificielle avec une API comme celle de GPT-4. C’est rapide, facile, et ça marche dès le premier jour. Vous écrivez un prompt, vous appelez l’API, et vous avez une réponse qui semble intelligente. Mais quand votre prototype passe de 100 requêtes par jour à 10 000, tout change. Le coût explose. La latence devient un cauchemar. Vos données partent sur des serveurs externes. Et pire : un jour, l’API change sans prévenir, et votre application ne fonctionne plus comme avant.
Le prototypage rapide avec des API : la voie la plus facile
Quand vous débutez, les API propriétaires comme OpenAI, Anthropic ou Google Gemini sont incontournables. Elles vous donnent accès aux meilleurs modèles du moment sans avoir à gérer un seul GPU. Avec LangChain, vous assemblez des chaînes de prompts en quelques heures. Avec un notebook Python, vous testez des idées en minutes. C’est comme construire une maquette en carton : vous ne vous souciez pas de la structure, vous voulez juste voir si l’idée fonctionne.
Un client de santé dans le Nord de la Caroline a utilisé GPT-4 API pour prototyper un système qui résumait les dossiers médicaux. En deux semaines, ils avaient un MVP qui réduisait le temps de lecture de 45 minutes à 7 minutes. Les médecins étaient émerveillés. Le problème ? À 500 requêtes par jour, la facture mensuelle dépassait 3 200 $. À 5 000 requêtes, elle montait à 18 000 $. Et chaque fois que l’API était lente, les utilisateurs abandonnaient.
Les API sont parfaites pour tester une hypothèse. Elles ne sont pas conçues pour tenir debout quand vous avez des milliers d’utilisateurs actifs chaque jour.
La mise en production avec des LLM open-source : la vraie difficulté
Pour passer en production, vous devez sortir du monde des API. Cela signifie déployer des modèles open-source comme Llama 3, Mistral, ou Phi-3 sur vos propres serveurs. Cela demande des compétences en MLOps, des GPU puissants, et une architecture bien pensée. Mais c’est la seule façon de contrôler ce qui se passe.
La même équipe de santé a migré vers un modèle Mistral 7B fine-tuné avec LoRA, déployé sur AWS SageMaker avec des NVIDIA A10G. Le résultat ?
- Coût réduit de 45 % : de 18 000 $ à 9 900 $ par mois pour le même volume
- Latence divisée par deux : 1,2 seconde par document contre 2,8 secondes avec l’API
- Données jamais quittées leurs serveurs : respect total du HIPAA
- Précision améliorée de 12 % selon les scores ROUGE pour les résumés médicaux
Le secret ? Pas de per-token pricing. Pas de dépendance à un fournisseur. Pas de surprises. Vous payez pour le matériel, pas pour chaque mot généré.
Les pièges de la transition : ce que personne ne vous dit
La plupart des projets échouent ici. Pas parce que la technologie ne marche pas. Mais parce que les équipes ne s’attendent pas à ce que la production soit un tout autre jeu.
En prototypage, vous testez 20 cas. En production, vous devez gérer 20 000 variations de requêtes. Un médecin écrit "migraine chronique avec nausées". Un autre écrit "je me sens mal depuis 3 semaines, j’ai mal à la tête et je vomis". Votre modèle doit comprendre les deux. Avec une API, vous n’avez pas accès à ces données. Avec un modèle auto-hébergé, vous pouvez les collecter, les analyser, et améliorer votre modèle semaine après semaine.
Et puis il y a la dérive des prompts. Un prompt qui marche en développement peut devenir inefficace en production. Pourquoi ? Parce que les utilisateurs ne parlent pas comme vous avez imaginé. Vous devez surveiller les changements en temps réel. Avec LangSmith, vous comparez chaque sortie à un baseline. Si la qualité baisse de plus de 5 %, vous êtes alerté. Sans ça, vous ne savez même pas que votre système dégénère.

Le compromis intelligent : une architecture hybride
Vous n’avez pas à choisir entre API et open-source. La meilleure solution est souvent les deux.
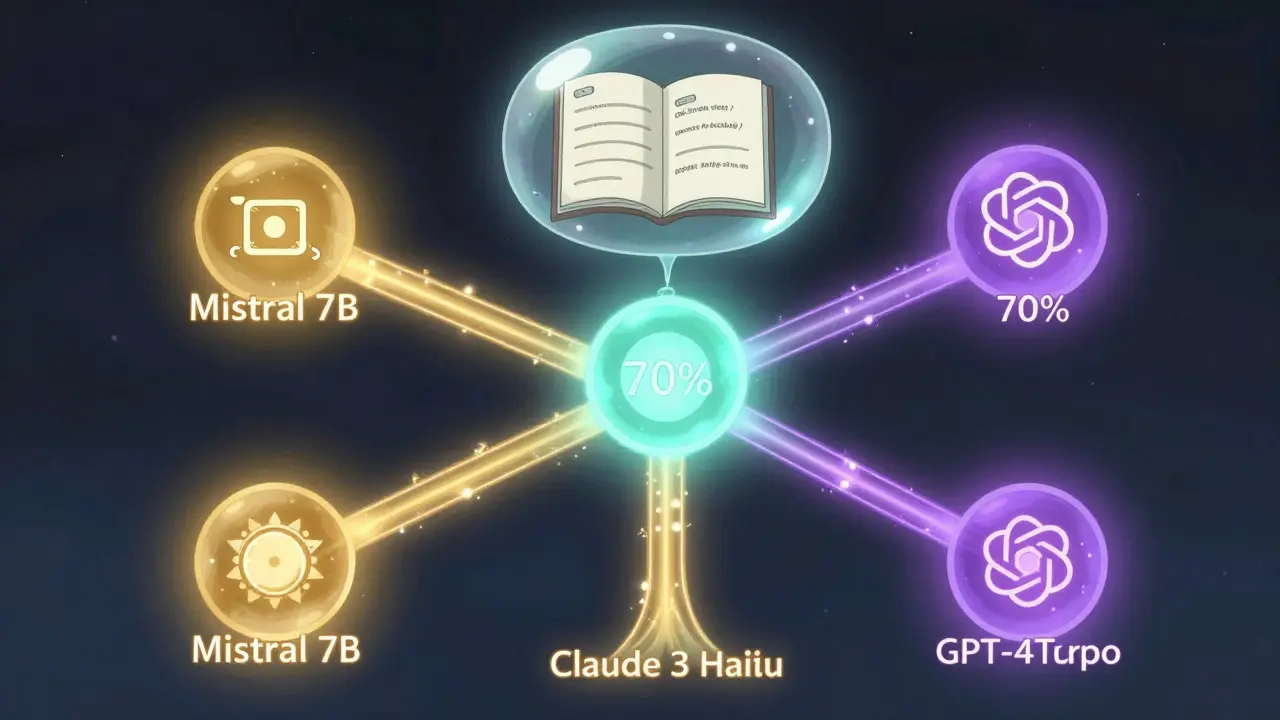
Une entreprise de droit dans l’Ohio a mis en place un système de routage intelligent :
- 70 % des requêtes vont à un modèle Mistral 7B auto-hébergé (coût bas, latence stable)
- 20 % à une API de milieu de gamme comme Claude 3 Haiku (pour couvrir des cas rares)
- 10 % à GPT-4 Turbo (pour les cas extrêmes où la précision prime sur le coût)
Cela a réduit leur facture globale de 72 %, tout en maintenant une qualité élevée. Et si l’API Claude 3 a un bug un jour ? Vous pouvez la désactiver sans toucher au reste du système.
Le cache sémantique renforce encore cette stratégie. Si un utilisateur pose la même question que quelqu’un d’autre la semaine dernière, vous renvoyez la réponse précédente. Pour des contrats juridiques ou des dossiers médicaux répétitifs, cela donne des taux de cache de 60 à 70 %. C’est comme avoir un assistant qui se souvient de tout ce qu’il a déjà vu.
Les outils qui font la différence en production
En prototypage, vous utilisez Jupyter, LangChain, et une API. En production, vous avez besoin d’un système complet.
- LangSmith : pour surveiller la qualité des réponses, détecter les erreurs et les dérives
- Prometheus + Grafana : pour suivre la latence, le nombre de requêtes, et les erreurs en temps réel
- MLflow ou DVC : pour versionner vos modèles, comme vous versionnez du code
- NGINX ou Istio : pour gérer les déploiements canari, les bascules, et la sécurité
- Vector stores (Pinecone, Qdrant) : pour stocker et retrouver des contextes similaires, améliorant la précision
Un seul outil manquant, et votre système devient une boîte noire. Vous ne savez pas pourquoi ça marche. Ni pourquoi ça ne marche plus.
Quand passer à l’auto-hébergement ?
Il n’y a pas de règle universelle. Mais voici les signaux clairs que vous êtes prêt :
- Vous dépensez plus de 5 000 $ par mois en API
- Vos requêtes dépassent 1 000 par jour
- Vos données sont sensibles (santé, finance, juridique)
- Vous avez besoin de latence inférieure à 2 secondes
- Vous avez une équipe capable de gérer des serveurs GPU (ou vous pouvez en embaucher une)
Si vous répondez oui à au moins trois de ces points, vous êtes déjà en train de perdre de l’argent en gardant l’API.
La vérité sur la "cliff de production"
Les entreprises ont des centaines de prototypes fonctionnels. Mais très peu ont des systèmes en production. Pourquoi ?
Parce que la production n’est pas une question de technologie. C’est une question de maturité opérationnelle. Vous devez accepter que :
- Les modèles d’IA ne sont pas des logiciels classiques : deux fois la même entrée peut donner deux sorties différentes
- Les fournisseurs d’API peuvent changer leurs modèles sans préavis
- Le coût ne se calcule plus en heures de développement, mais en millions de tokens par mois
- Vous devez mettre en place des processus de révision humaine, de monitoring continu, et de mise à jour régulière
Le prototypage avec API est un sprint. La production avec LLM open-source est un marathon. Et pour gagner, vous devez changer votre façon de penser.
Pourquoi les API sont-elles si coûteuses en production ?
Les API cobrent chaque token généré ou lu. Un document de 500 mots peut coûter 0,03 $ avec GPT-4. À 10 000 documents par jour, cela fait 300 $ par jour, soit 9 000 $ par mois. Si votre système génère des réponses en boucle (par exemple, un agent qui répète des appels), les coûts peuvent exploser à des dizaines de milliers de dollars en quelques heures. Avec un modèle auto-hébergé, vous payez une fois pour le GPU, puis vous générez autant de tokens que vous voulez sans frais supplémentaires.
Est-ce que je dois tout migrer d’un coup vers un modèle open-source ?
Non. La meilleure approche est progressive. Commencez par déplacer les requêtes les plus répétitives et les moins sensibles. Testez le modèle open-source sur 10 % du trafic. Comparez les résultats avec l’API. Si la qualité est équivalente ou supérieure, augmentez progressivement. Utilisez un routage intelligent pour basculer en cas d’échec. Cela réduit les risques et vous permet d’apprendre en production.
Quels GPU sont nécessaires pour déployer un modèle open-source ?
Pour un modèle comme Llama 3 8B, un seul GPU NVIDIA A10G (24 Go) suffit. Pour Mistral 7B ou Llama 3 70B, vous avez besoin d’au moins un NVIDIA A100 (40 Go ou 80 Go). Avec la quantification (int8 ou int4), vous pouvez réduire la mémoire requise de moitié. Des cartes comme l’AWS Inferentia ou les GPU AMD MI300X offrent aussi de bonnes performances à moindre coût. Le choix dépend du volume de requêtes et de la latence acceptable.
Comment garantir la qualité des réponses en production ?
Vous ne pouvez pas vous fier à des tests manuels. Vous avez besoin d’un système hybride : 1) des métriques automatiques (ROUGE, BLEU, exact match) sur 100 % des réponses ; 2) un modèle d’évaluation (comme GPT-4) qui note 10 % des réponses pour détecter les dérives ; 3) une révision humaine pour 5 % des cas critiques (ex. : diagnostics médicaux ou décisions juridiques). Sans cette triple couche, vous risquez de délivrer des réponses dangereuses sans vous en rendre compte.
Les modèles open-source sont-ils aussi performants que les API propriétaires ?
Pour les tâches générales, oui. Pour les cas très spécifiques, pas toujours. Mais la clé est le fine-tuning. Un modèle Mistral 7B fine-tuné sur vos données internes (contrats, dossiers médicaux, FAQ clients) peut surpasser GPT-4 sur vos tâches spécifiques. Les API sont optimisées pour le tout-terrain. Les modèles auto-hébergés sont optimisés pour votre terrain. Et dans la production, c’est ce dernier qui gagne.
Le futur de l’IA n’est pas dans l’exclusivité. C’est dans la combinaison intelligente : utiliser les API pour explorer, et les modèles open-source pour produire. Ceux qui comprennent cette transition avant les autres gagneront. Les autres se retrouveront avec une facture astronomique et un système qui ne fonctionne plus.










