
Les modèles de langage à grande échelle (LLM) comme GPT-4, Llama 3 ou Gemini ne sont pas des boîtes noires magiques. Ils fonctionnent grâce à trois composants fondamentaux qui travaillent ensemble comme les pièces d’une horloge précise : les embeddings, l’attention et les réseaux feedforward. Si vous avez déjà essayé de comprendre comment ces modèles génèrent du texte, vous avez probablement été perdu dans un flot de termes techniques. Voici une explication claire, sans jargon inutile, de ce qui se passe vraiment à l’intérieur.
Les embeddings : transformer les mots en nombres
Un modèle de langage ne « lit » pas les mots comme vous ou moi. Il ne connaît pas le sens de « chat » ou de « voiture ». Il ne voit que des nombres. C’est ici que les embeddings entrent en jeu.
Chaque mot (ou sous-mot, comme « déplacement » divisé en « déplac » et « ement ») est converti en une liste de nombres, généralement entre 768 et 12 288 chiffres. Cette liste est appelée un vecteur d’embedding. L’idée est simple : des mots qui ont des sens proches doivent avoir des vecteurs proches dans cet espace numérique. Par exemple, le vecteur de « roi » sera très proche de celui de « reine », et la différence entre « roi » et « reine » ressemblera à la différence entre « homme » et « femme ».
Ce n’est pas un hasard. Les embeddings apprennent ces relations à partir de millions de phrases. Si vous lisez des milliards de textes, vous finissez par savoir que « Paris » est souvent suivi de « France », et que « médecin » est souvent associé à « hôpital ». Ces associations se transforment en positions dans un espace multidimensionnel.
Et ce n’est pas tout. Les embeddings incluent aussi des informations de position. Puisque les modèles traitent tous les mots en même temps (contrairement aux anciens systèmes qui les lisaient un par un), ils ont besoin de savoir quel mot vient avant ou après. C’est pourquoi on ajoute des embeddings de position : une autre couche de nombres qui dit au modèle « ce mot est le 12e dans la phrase ». Des versions modernes comme RoPE (Rotary Position Embedding), utilisées dans Llama, améliorent encore cela en permettant au modèle de comprendre la position même pour des phrases bien plus longues que celles vues pendant l’entraînement.
L’attention : comprendre les liens entre tous les mots
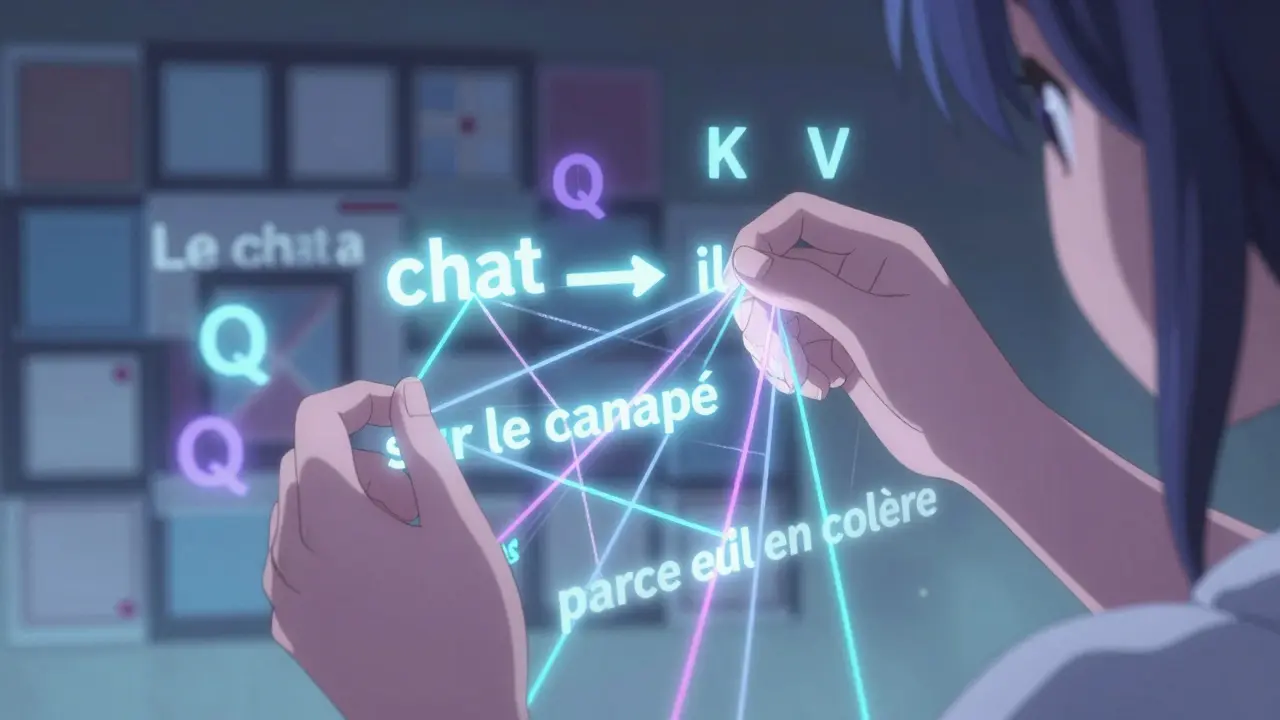
Les embeddings donnent une représentation de chaque mot, mais ils ne disent pas comment ces mots se relient entre eux. C’est là que l’attention entre en scène - et c’est la partie la plus révolutionnaire des modèles modernes.
Imaginez que vous lisez cette phrase : « Le chat a sauté sur le canapé parce qu’il était en colère. » Vous savez que « il » fait référence à « chat », pas à « canapé ». Un ancien modèle aurait eu du mal à le deviner. Mais un modèle avec attention, lui, calcule une « note d’attention » pour chaque paire de mots. Il se demande : « Quelle est l’importance du mot “chat” pour comprendre le mot “il” ? »
Chaque mot est transformé en trois vecteurs : Query (Q), Key (K) et Value (V). Le modèle compare chaque Query avec toutes les Keys pour obtenir des scores d’attention. Ces scores sont ensuite normalisés avec une fonction softmax - ce qui donne une distribution de probabilités. Enfin, chaque Value est pondérée par ces probabilités, et le résultat est sommé pour produire une nouvelle représentation du mot.
Le vrai pouvoir vient du multi-head attention. Plutôt qu’un seul calcul d’attention, le modèle en fait plusieurs en parallèle - 32, 64, ou même 96 dans GPT-3. Chaque « tête » se concentre sur un type différent de relation : une tête regarde les relations grammaticales, une autre les liens sémantiques, une autre les répétitions. Ensemble, elles forment une compréhension riche et nuancée.
Les modèles comme Llama 2 ont amélioré cela avec le grouped-query attention : au lieu de calculer des Key et Value pour chaque tête, elles partagent certaines d’entre elles. Cela réduit la mémoire utilisée sans sacrifier la performance - une avancée cruciale pour rendre les modèles plus rapides et moins chers à faire tourner.
Les réseaux feedforward : transformer les informations
Après l’attention, chaque mot a une nouvelle représentation, enrichie par son contexte. Mais ce n’est pas encore fini. Cette représentation passe ensuite dans un réseau feedforward - une petite machine à calculer qui transforme encore les données.
Ce réseau est très simple : deux couches linéaires avec une fonction d’activation (souvent GELU) entre les deux. La première couche élargit le vecteur - par exemple, de 768 à 3 072 nombres - puis la deuxième le réduit de nouveau à 768. Ce n’est pas une simple multiplication. C’est une transformation non linéaire : le modèle apprend à réorganiser les informations, à mettre en avant ce qui est important, à ignorer ce qui est bruit.
Contrairement à l’attention, qui traite les relations entre mots, le feedforward travaille sur chaque mot indépendamment. C’est pourquoi il est souvent appelé « position-wise ». Il ne sait pas si le mot est au début ou à la fin de la phrase - il ne voit que le vecteur qui lui est donné.
Et pourtant, c’est cette couche qui permet au modèle de faire des sauts conceptuels. Si l’attention dit « ce mot est lié à celui-là », le feedforward décide « maintenant que je sais ça, comment je le réinterprète ? » C’est ici que se cachent certaines des capacités émergentes des LLM : la logique, l’humour, la métaphore. Pas parce qu’on leur a appris à faire ça, mais parce que les combinaisons de millions de transformations ont créé des patterns inattendus.
Le tout ensemble : comment tout s’emboîte
Chaque composant ne fonctionne pas seul. Ils sont empilés en blocs identiques, appelés blocs Transformer. Un bloc typique ressemble à ça :
- Embedding du mot + embedding de position
- Normalisation des couches (LayerNorm)
- Attention multi-tête
- Connexion résiduelle (on ajoute l’entrée initiale à la sortie)
- Normalisation des couches à nouveau
- Réseau feedforward
- Connexion résiduelle à nouveau
La connexion résiduelle est cruciale. Sans elle, les modèles profonds (comme GPT-3 avec 96 blocs empilés) ne pourraient jamais s’entraîner - les signaux s’effacent en traversant les couches. Avec elle, chaque bloc peut se concentrer sur améliorer un peu la représentation, sans avoir à tout réapprendre depuis le début.
Et ce bloc est répété des dizaines, voire des centaines de fois. Plus il y a de blocs, plus le modèle peut faire de transformations fines. C’est pourquoi GPT-3 avec 175 milliards de paramètres est si puissant : chaque bloc ajoute une couche de compréhension. Il ne s’agit pas d’un seul grand calcul - c’est une série de petits ajustements, répétés, qui finissent par produire du texte fluide, cohérent, parfois même créatif.
Différences entre les modèles : GPT, BERT, Llama
Tous les modèles ne sont pas faits pareil. Les différences les plus importantes viennent de la manière dont l’attention est utilisée.
Les modèles comme GPT et Llama sont autoregressifs. Ils génèrent du texte mot par mot, en ne regardant que les mots précédents. Leur attention est « causale » : un mot ne peut pas « voir » les mots qui viennent après. C’est pourquoi ils sont excellents pour la génération de texte.
En revanche, BERT est bidirectionnel. Il voit tout le contexte en même temps - les mots avant et après. C’est parfait pour comprendre une phrase, répondre à une question ou remplacer un mot manquant. Mais il ne peut pas générer du texte lui-même, car il n’a pas de structure pour prédire le prochain mot.
Llama 3, sorti en avril 2024, utilise une variante appelée « adaptive feedforward expansion ». Elle ajuste la taille du réseau feedforward selon la complexité du mot. Pour un mot simple comme « le », il utilise une petite couche. Pour un mot comme « anthropomorphisation », il augmente la puissance de calcul. Cela rend le modèle plus efficace : moins de ressources gaspillées sur les mots simples, plus de puissance pour les mots complexes.

Les limites et les défis
Malgré leur puissance, ces composants ont des faiblesses.
Le principal problème est la complexité quadratique de l’attention. Pour une phrase de 10 000 mots, le modèle doit calculer 100 millions de relations entre mots. Pour une phrase de 100 000 mots, ce sont 10 milliards de calculs. C’est pourquoi les modèles comme Gemini 1.5, capables de traiter un million de tokens, nécessitent des centaines de gigaoctets de mémoire et des GPU très puissants.
De plus, les embeddings peuvent capturer des biais. Si les données d’entraînement contiennent des stéréotypes (ex. : « infirmière » est souvent associée à « femme »), le modèle les apprendra. Les réseaux feedforward, eux, sont des boîtes noires : on ne sait pas exactement comment ils transforment les informations. C’est une des raisons pour lesquelles il est difficile de comprendre pourquoi un modèle donne une réponse spécifique.
Et puis il y a le problème de la cohérence sur de longues séquences. Un modèle peut bien comprendre les 500 premiers mots d’un texte, mais perdre le fil au bout de 5 000. Les chercheurs travaillent sur des solutions comme l’attention relative ou les mémoires externes, mais rien n’est encore parfait.
Que retient-on ?
Les modèles de langage ne sont pas des esprits artificiels. Ce sont des systèmes mathématiques sophistiqués, construits sur trois idées simples mais puissantes :
- Les embeddings transforment les mots en vecteurs qui capturent leur sens et leur position.
- L’attention permet de comprendre les relations entre tous les mots, en parallèle.
- Les réseaux feedforward transforment ces relations en représentations plus riches et plus abstraites.
Et c’est leur combinaison - répétée des centaines de fois - qui permet aux LLM de générer du texte, de répondre à des questions, de coder, et même de raconter des histoires. Ce ne sont pas des miracles. Ce sont des mathématiques. Et comprendre ces composants, c’est comprendre pourquoi ces modèles fonctionnent… et où ils risquent de tomber en panne.
Pourquoi les embeddings sont-ils si importants dans les modèles de langage ?
Les embeddings transforment les mots en nombres de manière à ce que des mots avec des sens similaires soient proches dans l’espace vectoriel. Sans cette étape, le modèle ne pourrait pas comprendre le sens des mots. Par exemple, « roi » et « reine » auront des vecteurs très proches, et la différence entre eux ressemblera à la différence entre « homme » et « femme ». C’est cette structure qui permet aux modèles de faire des analogies et de capturer des relations sémantiques sans avoir été explicitement programmés pour cela.
Quelle est la différence entre attention et feedforward ?
L’attention s’occupe des relations entre les mots : elle détermine quels mots sont importants pour comprendre un autre mot. Le feedforward, lui, traite chaque mot individuellement pour transformer sa représentation - il ajoute de la complexité et de l’abstraction. En résumé : l’attention dit « quel mot est lié à quoi », et le feedforward dit « maintenant que je sais ça, comment je le réinterprète ? »
Pourquoi les modèles comme GPT utilisent-ils l’attention causale ?
L’attention causale empêche un mot de « voir » les mots qui viennent après lui. C’est essentiel pour la génération de texte : si vous écrivez une phrase mot par mot, vous ne pouvez pas utiliser le mot suivant pour le prédire. C’est pourquoi GPT et Llama sont des modèles autoregressifs - ils génèrent du texte en se basant uniquement sur ce qui a déjà été écrit.
Qu’est-ce que le multi-head attention et pourquoi est-ce utile ?
Le multi-head attention permet au modèle de regarder les relations entre les mots sous plusieurs angles en même temps. Chaque « tête » peut se concentrer sur un type différent de lien : grammatical, sémantique, de répétition, de dépendance. Cela permet au modèle de capturer une compréhension plus riche du langage. Par exemple, une tête peut détecter que « il » fait référence à « chat », une autre peut repérer une structure de phrase, et une troisième peut capter un ton ironique.
Pourquoi les réseaux feedforward sont-ils appelés « position-wise » ?
Parce qu’ils appliquent exactement la même transformation à chaque mot, indépendamment de sa position dans la phrase. Contrairement à l’attention, qui compare les mots entre eux, le feedforward ne regarde que le vecteur de chaque mot seul. C’est pourquoi il est « position-wise » : il agit sur chaque position de la même manière, sans tenir compte du contexte global.
Quel est le plus grand défi technique aujourd’hui pour les LLM ?
Le plus grand défi est la complexité computationnelle de l’attention. Pour des séquences très longues (plus de 10 000 mots), le nombre de calculs augmente au carré du nombre de mots. Cela rend les modèles lents et coûteux. Les chercheurs travaillent sur des solutions comme l’attention linéaire, les mémoires externes ou les architectures hybrides, mais aucune n’a encore remplacé l’attention classique pour les tâches de haute qualité.











